Lexicography
Scientific and evidence-based; contemporary and historical, , phraseology, neologisms, central knowledge base
Grammar
Reference grammar of Dutch in Dutch and English
Terminology
Resource collection, tools for collaborative terminology, comparative legal dictionary
Contemporary Dutch
Corpora of contemporary Dutch, neologisms and trends, grammar, terminology and dictionaries
Historical Dutch
Historical corpora, lexicons, dictionaries and datasets
Dialectology
Dialect lexicography and spoken dialect corpora
INT’s Dutch language data in a nutshell
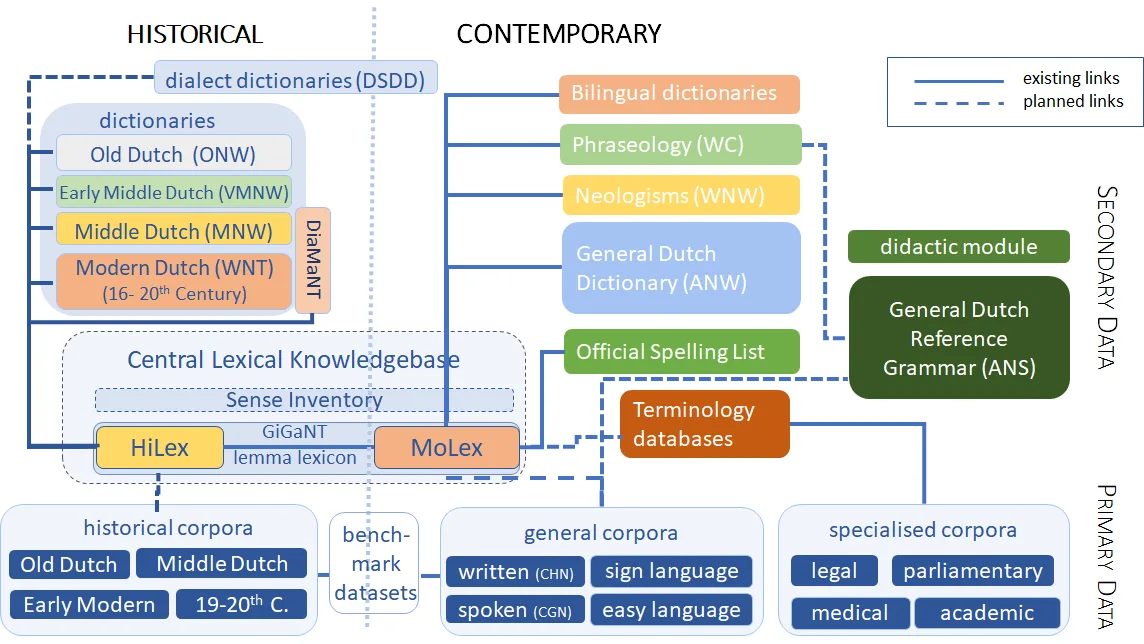
The Dutch Language Institute’s language databases document Dutch in all its variety. In addition to a division into historical and contemporary language data, a distinction can also be made between primary and secondary data. The primary data consists of language use that is representative of the different varieties of Dutch. The INT has built up extensive expertise and developed language software to linguistically enrich raw language data (text, audio, video) and add rich metadata. This data processing results in linguistic corpora for a wide range of language varieties that are made available and searchable for research purposes. The secondary data consists of databases with a systematic and scientifically underpinned description of the Dutch language that is based on evidence from the primary corpus data. The INT develops both lexical and grammatical databases that can be searched via online applications. In recent years, the INT has also been integrating these various databases into, what is called, a language infrastructure: on the one hand, the databases are increasingly linked to each other and to other databases at the European level, enabling their combined use in research and development. On the other hand, these databases are also being made more widely available to researchers and developers via APIs or as open data via our repository, following the principles of sustainable and FAIR-access to language resources.